Dereverberation in Acoustic Sensor Networks using Weighted Prediction Error with Microphone-dependent Prediction Delays
Acoustic scenario
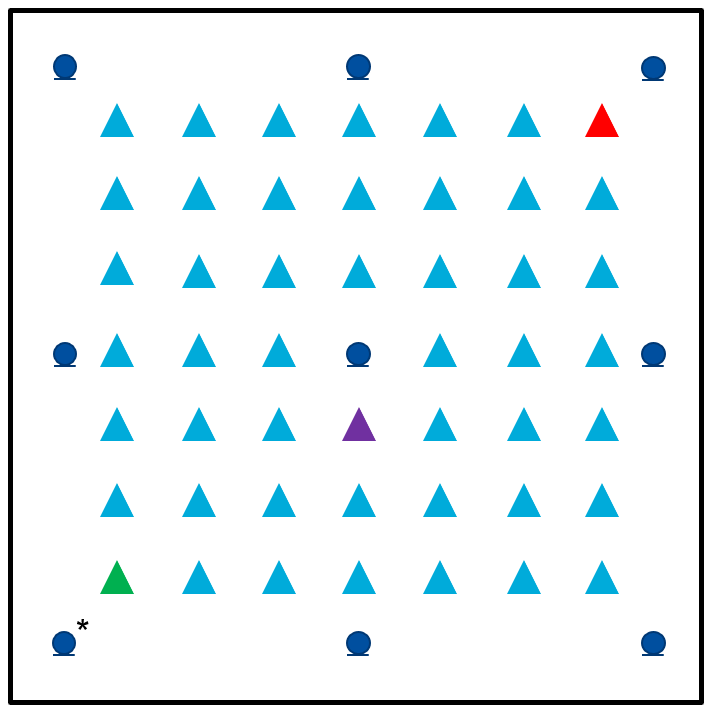
- Acoustic sensor network with 9 spatially-distributed microphones with reference microphone (*)
- 48 total considered positions of single speech source
- Available audio examples for 3 color-coded positions
- Reverberation time T60: 500 ms, 750ms, 1000ms
- TDOA compensation using estimated TDOAs
- MI: WPE with microphone-independent prediction delay
- MD-NINT: WPE with microphone-dependent prediction delays using crossband filtering
- MD-NINT-B2B: WPE with microphone-dependent prediction delays using band-to-band approximation
- MD-INT: WPE with integer microphone-dependent prediction delays
Reverberation time T60: 500 ms
| Source Position | Reverberant | MI | MD-NINT (Estimated TDOA) | MD-NINT-B2B (Estimated TDOA) | MD-INT (Estimated TDOA) |
|---|---|---|---|---|---|
1 |
|||||
2 |
|||||
3 |
Reverberation time T60: 750 ms
| Source Position | Reverberant | MI | MD-NINT (Estimated TDOA) | MD-NINT-B2B (Estimated TDOA) | MD-INT (Estimated TDOA) |
|---|---|---|---|---|---|
1 |
|||||
2 |
|||||
3 |
Reverberation time T60: 1000 ms
| Source Position | Reverberant | MI | MD-NINT (Estimated TDOA) | MD-NINT-B2B (Estimated TDOA) | MD-INT (Estimated TDOA) |
|---|---|---|---|---|---|
1 |
|||||
2 |
|||||
3 |