Multiple External Microphones
Multiple External Microphones
RTF-steered binaural MVDR beamforming incorporating multiple external microphones
Nico Gößling, Wiebke Middelberg, Simon Doclo
Proc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, USA, Oct. 2019
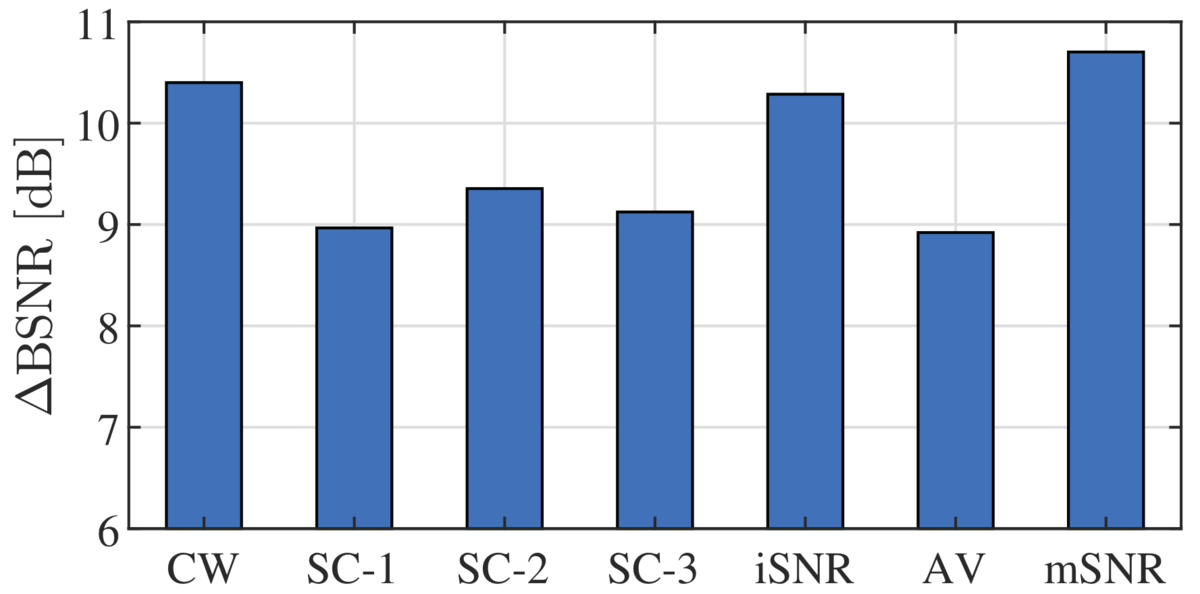
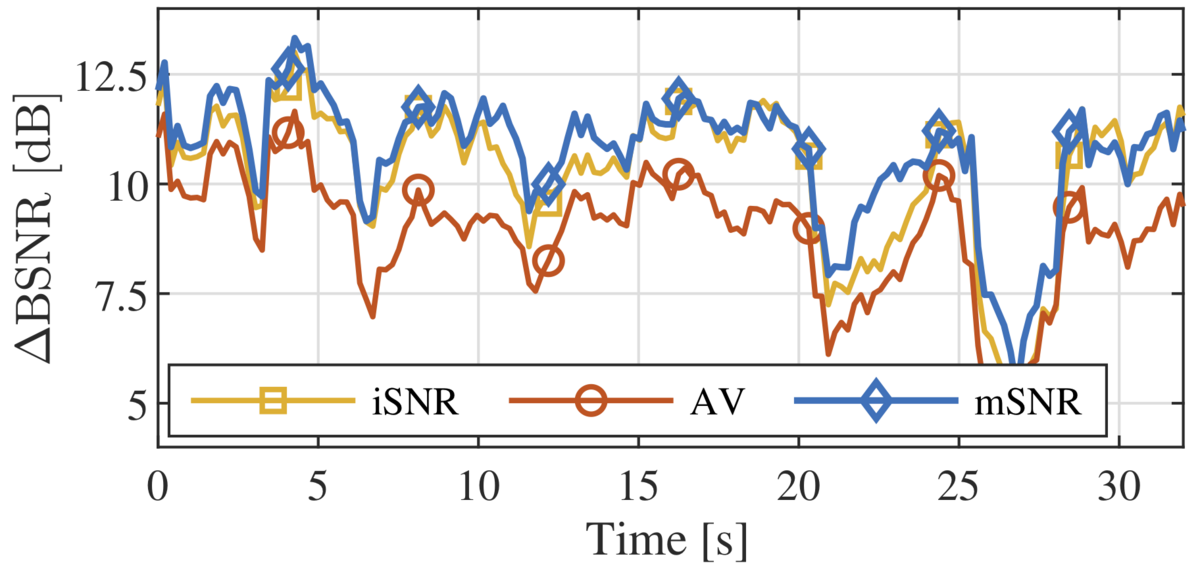
The binaural minimum-variance distortionless-response (BMVDR) beamformer is a well-known noise reduction algorithm that can be steered using the relative transfer function (RTF) vector of the desired speech source. Exploiting the availability of an external microphone that is spatially separated from the head-mounted microphones, an efficient method has been recently proposed to estimate the RTF vector in a diffuse noise field. When multiple external microphones are available, different RTF vector estimates can be obtained by using this method for each external microphone. In this paper, we propose several procedures to combine these RTF vector estimates, either by selecting the estimate corresponding to the highest input SNR, by averaging the estimates or by combining the estimates in order to maximize the output SNR of the BMVDR beamformer. Experimental results for a moving speaker and diffuse noise in a reverberant environment show that the output SNR-maximizing combination yields the largest binaural SNR improvement and also outperforms the state-of-the art covariance whitening method.
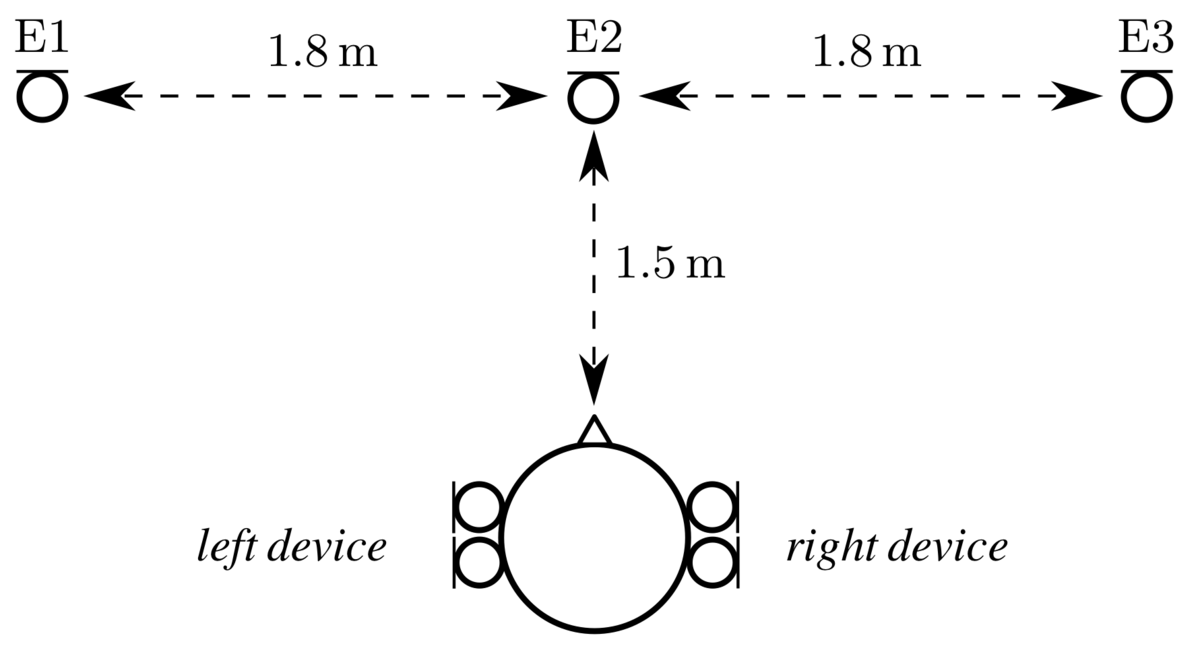
- 4 microphones of two BTE hearing devices mounted to the ears of a KEMAR dummy head
- 3 external microphones (E1, E2 and E3)
- Recorded in the Variable Acoustics Laboratory at the University of Oldenburg
- Reverberation time of about 400 ms
- Sampling rate 16 kHz
- STFT framework using a 32 ms square-root Hann window with 50% overlap
- Moving desired speech source (starting at E1, passing E2 and ending at E3)
- Pseudo-diffuse noise generated by four loudspeakers in the corners of the laboratory
- On-line implementation of the RTF-steered binaural MVDR beamformer using different RTF vector estimation methods
Sound examples (listen via headphones)
Input signals:
| Hearing device inputs (reference microphones): | |
| First external microphone (E1): | |
| Second external microphone (E2): | |
| Third external microphone (E3): |
Output Signals:
| Covariance Whitening (CW): | |
| SC method using E1 (SC-1): | |
| SC method using E2 (SC-2): | |
| SC method using E3 (SC-3): | |
| Input SNR-based selection (iSNR): | |
| Simple averaging (AV): | |
| SNR-maximizing combination (mSNR): |
Results