Semi-Supervised Learning
Contact
Head of lab
Lab Administration
Postal Address
Office Address
Semi-Supervised Learning
{kind=link}
Description
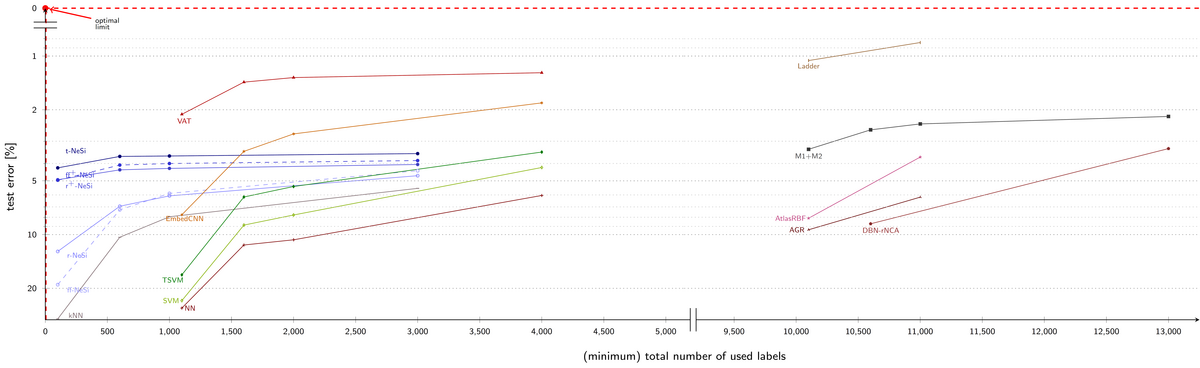
Our aim is to learn as high quality classifiers from as few labels in total as possible, for the whole tuning and training procedure. To achieve this goal, we use generative networks of three layers based on normalized hierarchical Poisson mixture models: The first layer performing input data normalization, the second learning data clusters based on Poisson noise assumptions, and the third learning the cluster classes. The result are compact hebbian update rules which do not require labeled data for parameter optimization in the clustering layer and only a minimal amount of labels in the classification layer. We use self-labeling mechanisms and truncated approximations to further enhance the semi-supervised performance of the network. With only a handful of free parameters, small validation set sizes can be used for their optimization, reducing the total number of neccessary labels far below the standard sizes for deep networks. Typical application domains of the approach are hand-written symbols (MNIST, EMNIST etc.) and text document classification. Please see the papers listed below for more details.
Source code is available on GitHub.
References (own publications)
D. Forster, A.-S. Sheikh and J. Lücke (2018)
Neural Simpletrons - Learning in the Limit of Few Labels with Directed Generative Networks
Neural Computation, 30:2113–2174 (online access, bibtex)
D. Forster and J. Lücke (2017)
Truncated Variational EM for Semi-Supervised Neural Simpletrons
International Joint Conference for Neural Networks (IJCNN), 3769-3776 (online access, bibtex)