BP Ch02 - Spam Filter -
BP Ch02 - Spam Filter -
Task Specification of a Simple Spam Filter
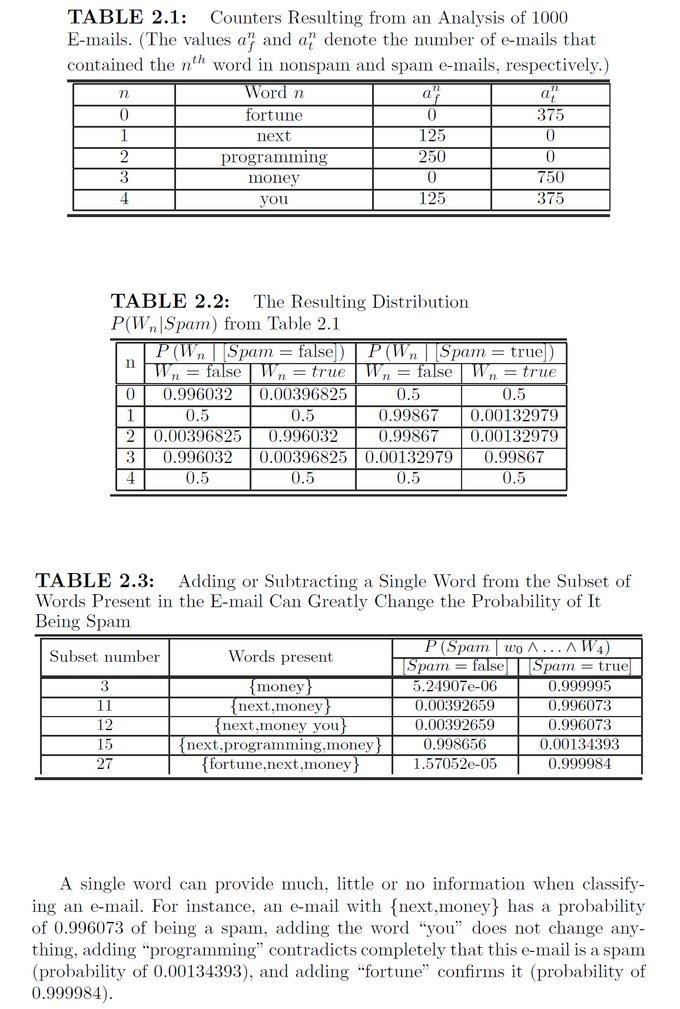
"If we consider a spam filter with an N word dictionary, then any given e-mail contains one and only one of the 2^N possible subsets of the dictionary. Here we restrict our spam filter to a five word dictionary so that we can analyze the 2^5 = 32 subsets. Assume that a set of 1000 e-mails is used in the identification phase and that the resulting numbers of nonspam are 250 and 750 respectively. Assume also that the resulting counter tables for a(n,f) and a(n,t) are those shown in Table 2.1 and the corresponding distribution P(W(n)|Spam) is given in Table 2.2." (Bessiere et al., BP, 2014, p.32f).
The conditional probabilities P(W(i) | Spam) in Table 2.2 were derived from the word countings in Table 2.1 according a transformation which the authors claim to be an instance of Laplace's succession law (Bessiere et al., 2014, p.27). The interval of the according conditional probabilities is 0 < P(W(i) | Spam) < 1 though the interval of the underlying untransformed naive relative frequencies is 0 <= {a(i,*)/a(*), (a(*)-a(i,*))/a(*)} <= 0. By this transformation it is impossible to estimate the impossible event P(...) = 0 or the certain event P(...) = 1 by empirical relative frequencies. Furthermore, before any observation is made all events are equal with probability P(...) = 1/|W(i)|. Because the authors' formulae are a bit misleading (Bessiere, et al., 2014, p.27) we present the complete set of formulae we need for the conditional probability table (CPT) in the table below:
| Spam | |||
|---|---|---|---|
| false | true | ||
Word(i) |
false | P(W(i)=f | Spam=f) = (|W(i)|-1+a(f)-a(i,f))/(|W(i)|+a(f)) | P(W(i)=f| Spam=t) = (|W(i)|-1+a(t)-a(i,t))/(|W(i)|+a(t)) |
true | P(W(i)=t | Spam=f) = (1+a(i,f))/(|W(i)|+a(f)) | P(W(i)=t | Spam=t) = (1+a(i,t))/(|W(i)|+a(t)) | |
- |W| = cardinality of the random variable W(i); for binary variables |W(i)| = 2
- a(f) = #(Spam=false)
- a(t) = #(Spam=true)
- a(i,f) = #(Word(i)=true, Spam=false)
- a(i,t) = #(Word(i)=true, Spam=true)
For binary variables the estimators for the conditional probabilities can be simplified to:
| Spam | |||
|---|---|---|---|
| false | true | ||
Word(i) |
false | P(W(i)=f | Spam=f) = (1+a(f)-a(i,f))/(2+a(f)) | P(W(i)=f| Spam=t) = (1+a(t)-a(i,t))/(2+a(t)) |
true | P(W(i)=t | Spam=f) = (1+a(i,f))/(2+a(f)) | P(W(i)=t | Spam=t) = (1+a(i,t))/(2+a(t)) | |
As an example we give the CPT for word 2 "Programming". The entries below correspond to the third line for word(2) in Table 2.2:
| Spam | |||
|---|---|---|---|
| false | true | ||
"Programming" |
false | P(W(i)=f | Spam=f) = (1+a(f)-a(i,f))/(2+a(f)) = (1+250-250)/(2+250) = 1/252 = 0.003968253968 | P(W(i)=f| Spam=t) = (1+a(t)-a(i,t))/(2+a(t)) = (1+750-0)/(2+750) = 751/752 = 0.9986702128 |
true | P(W(i)=t | Spam=f) = (1+a(i,f))/(2+a(f)) = (1+250)/(2+250) = 251/252 = 0.996031746 | P(W(i)=t | Spam=t) = (1+a(i,t))/(2+a(t)) = (1+0)/(2+750) = 1/752 = 0.001329787234 | |
The entries in the table (above) show that in non-Spam emails the occurence of the word "Programming" is with P("Programming=true | Spam=false)=0.9960 rather high. In contrast to that the probability for the word "Programming" is with P("Programming=true | Spam=true)=0.0013 rather low.
"It is now possible to compute the probability for an e-mail to be a spam or not given it contains or not each of the N words. This may be done using equation 2.32. Table 2.3 shows the obtained results for different subsets of words present in the e-mail.
A single word can provide much, little or no information when classifying an e-mail. For instance, an e-mail with {next, money} has a probability of 0.996073 of being a spam, adding the word “you” does not change anything, adding “programming” contradicts completely that this e-mail is a spam (probability of 0.00134393), and adding “fortune” confirms it (probability of 0.999984)." (Bessiere et al., BP, 2014, p.32f).
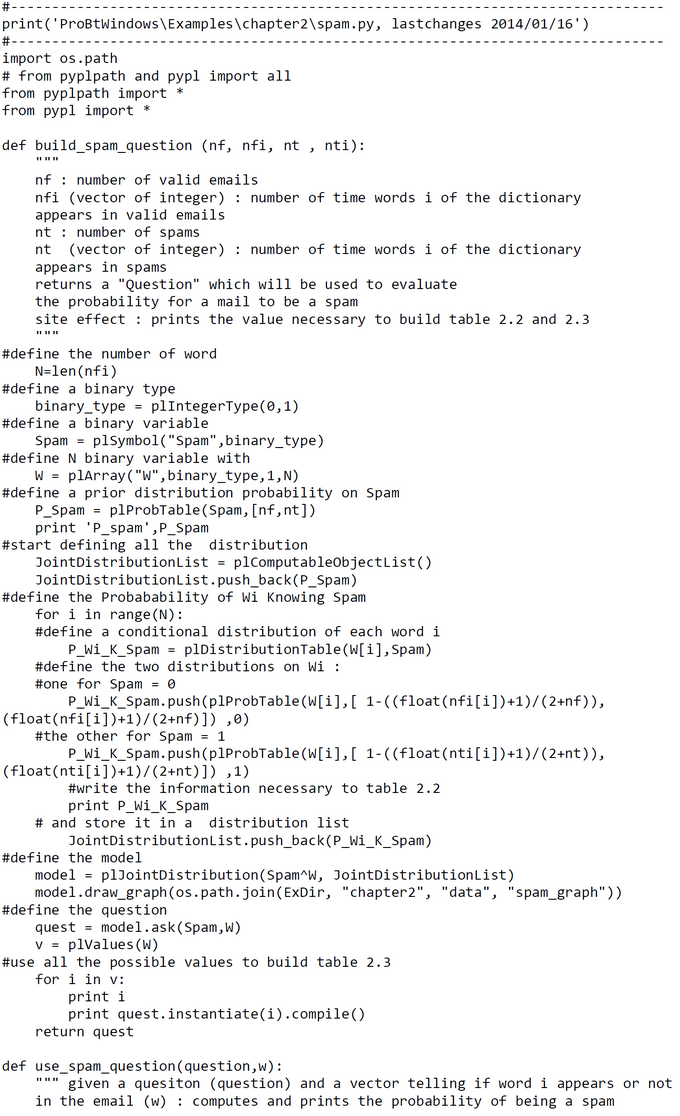
PROBT - Code and Test Run
This code was downloaded from the book's website and run according to the authors instructions.
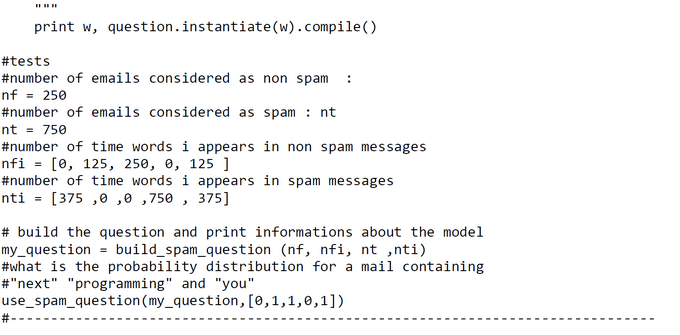


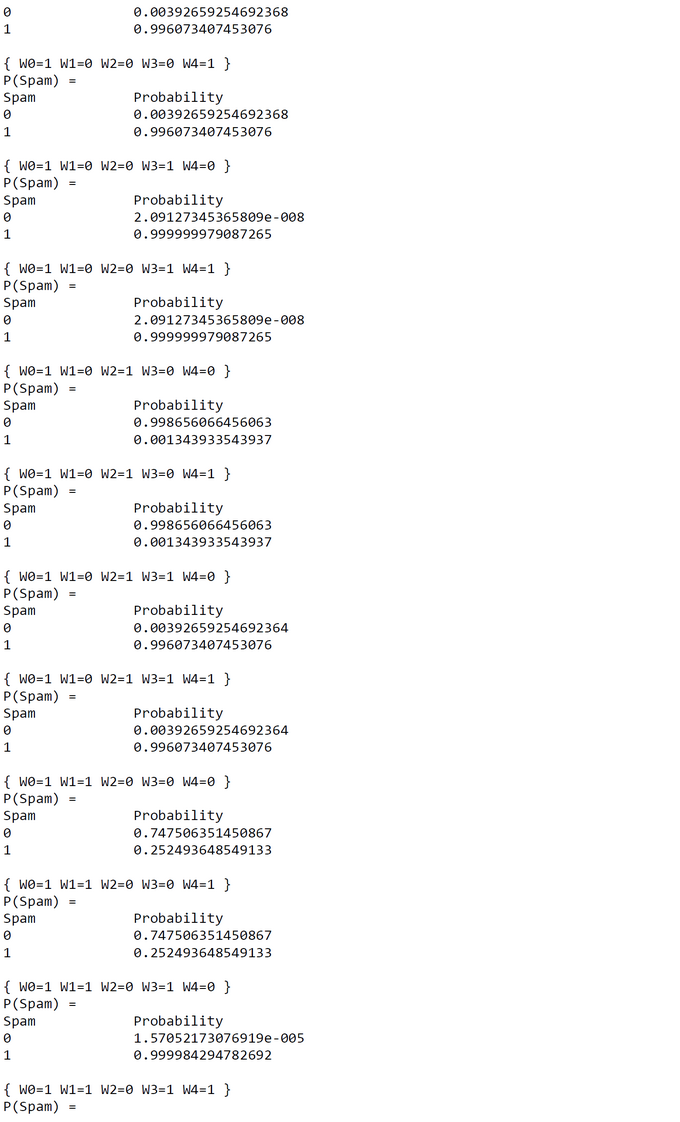

Augmented PROBT Code for Test Run with Intermediate Results
Because the original PROBT code and the API were hard to understand (even when consulting the documentation) I ran the code with many inserted 'prints'. The augmented code can be found here.




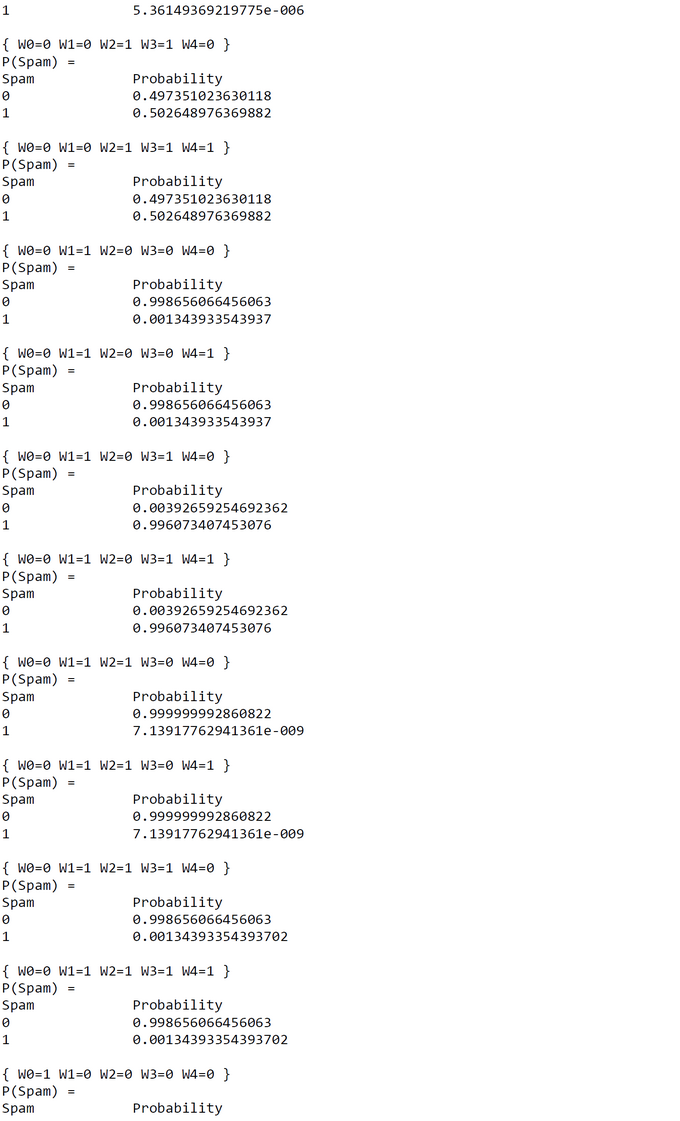
Test Run with Augmented Code











