Naive Bayesian Classifier
Naive Bayesian Classifier
Task Specification of a Spam Filter based on a Naive Bayesian Classifier
The task specification, the Laplacian correction of the frequency-based estimates of the model-relevant conditional probabilities, PROBT code of the model, and a PROBT test run can be found here.
CHURCH-Code and -Output for Naive Bayesian Classifier (Spam Filter)
The posterior conditional probabilities P(Spam | Evidence) in Table 2.3 (Bessiere et al, BP, 2014, p.33) were all obtained by using the exact variable-elimination algorithm in the C++-based PROBT software library. The implementation and results as provided by Bessiere et al. can be found here. Understanding the API and the documentation is very time-consuming as a comparison of the ProBT and WebCHURCH code convincingly shows.
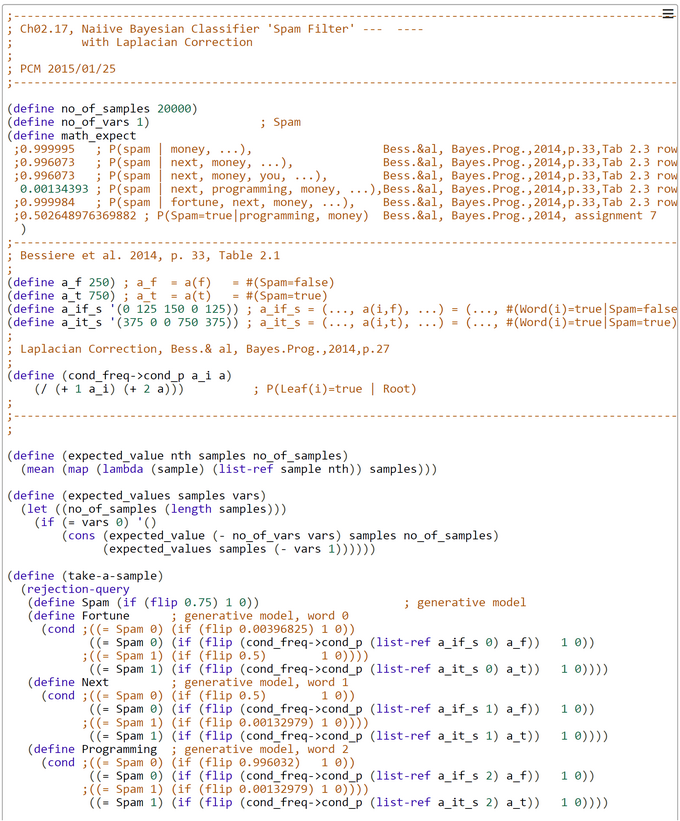
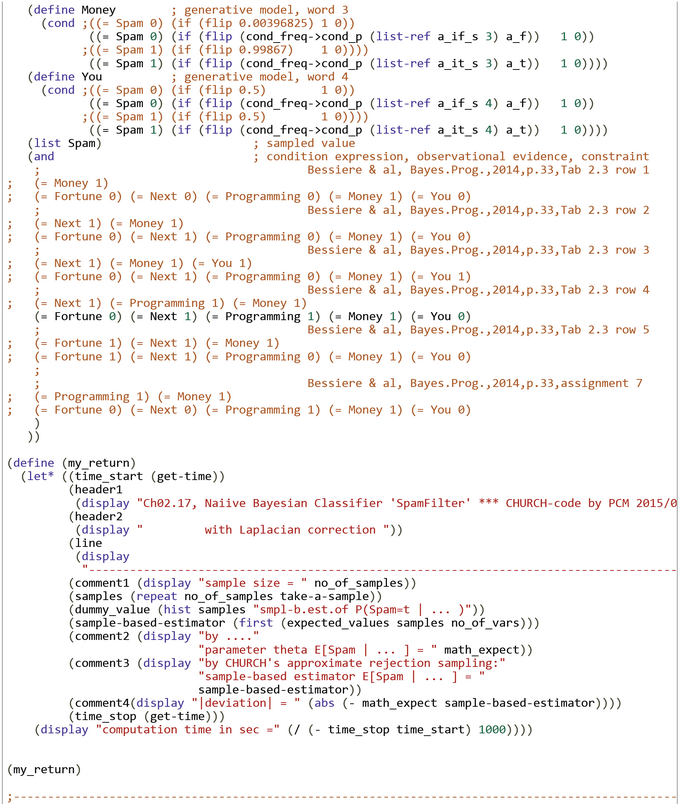
We model the spam filter within WebCHURCH in a rapid prototyping style. Approximate inferences are drawn with the transparent but (rather) inefficient rejection sampling algorithm.
Though being inefficient rejection sampling has one important advantage compared to MCMC-based approximate sampling schemes. The samples drawn by rejection-sampling possess the i.i.d.-property so that we can compute the precision of estimates by the Hoeffding formulas.
First we plugged into the WebCHURCH code the generative conditional probabilities from Table 2.2. The question arises how the missing words in the sets of Table 2.3 are treated. Are they 'don't care' variables ('Free' variables in BP terminology) or are they 'non-existing' variables ('known' but not observed in the emails). If the second alternative is true, then all five words have to be instantiated by evidence. The first alternative is called by us 'partial assignment' and the second 'full assignment'. In most cases the values of the conditional posterior probabilities will be different.
According to the computations with our Hoeffding bound function (code is here) we choose a sample size N=20000 and a upper deviation limit of epsilon=0.01. That guarantees a probability of deviation which is lower that 0.037:
P(|theta-estimator - theta| >= epsilon) <= 0.037
and
P(|theta-estimator - theta| >= 0.01) <= 0.037.
Results of our WebCHURCH runs are presented in the table below (the code is here). The absolute values of the deviations give strong evidence, that full assignments were used in the PROBT analyses. There is a trade-off between transparency of model semantics and run-time efficiency. The latter could be improved without loosing the first by abandoning the approximate rejections sampling algorithm by an exact one. But this has to be programmed explicitly from scratch in WebCHURCH.
| ass. | words present | partial assignment | full assignment | PROBT | ||||
|---|---|---|---|---|---|---|---|---|
| P(spam|.) | |deviat.| | sec | P(spam|.) | |deviat.| | sec | P(spam|..) | ||
| 3 | {money} | 0.9986 | 0.00144 | 0.8 | 1 | 0.00001 | 3.119 | 0.99999 |
| 8 | {programming, money} | 0.4924 | 0.01030 | 266 | 0.5025 | 0.00015 | 1180 | 0.50265 |
| 11 | {next, money} | 0.6646 | 0.33152 | 367 | 0.9955 | 0.00057 | 2368 | 0.99607 |
| 12 | {next, money, you} | 0.6655 | 0.33062 | 622 | 0.9959 | 0.00017 | 2072 | 0.99607 |
| 15 | {next,progr.,money} | 0.003 | 0.00166 | 1083 | 0.0014 | 0.00006 | 2294 | 0.00134 |
| 27 | {fortune, next, money} | 0.9964 | 0.00358 | 1121 | 1 | 0.00002 | 2292 | 0.99998 |
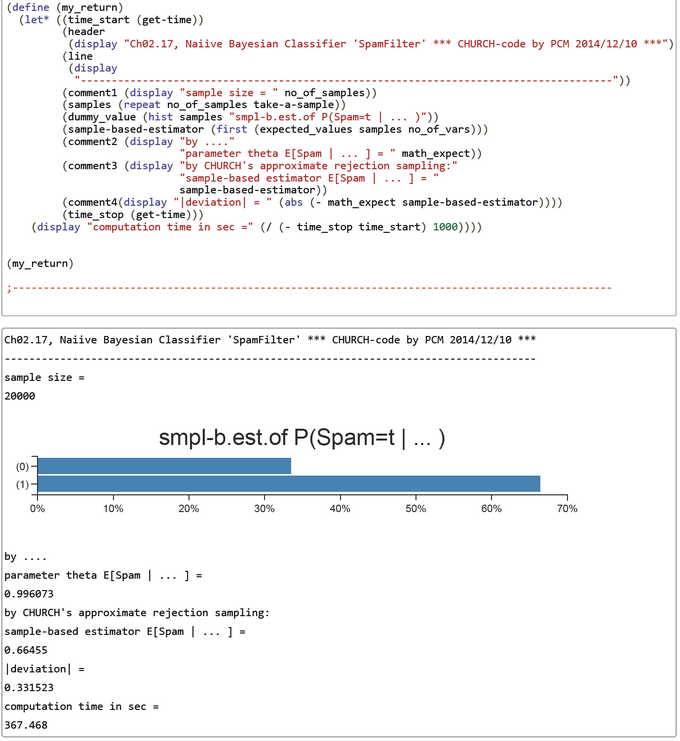
The WebCHURCH output (below) shows the rejection-sampled estimated posterior P(Spam=true | Next=true, Money=true) = 0.66455 with an |deviation| = 0.331523 from the true posterior P(Spam=true | next, money) = 0.996073.

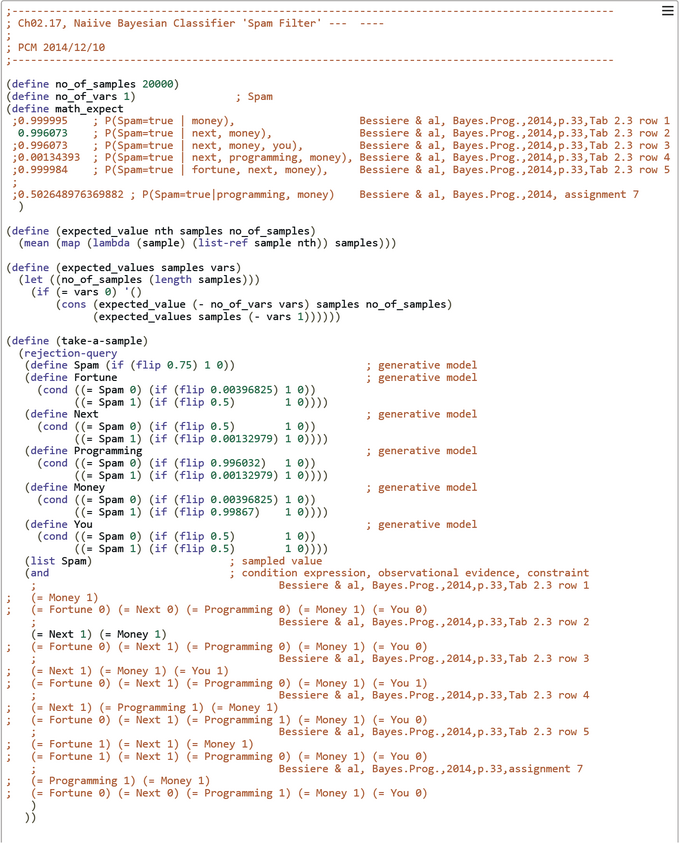
CHURCH-Code and -Output for Naive Bayesian Classifier (Spam Filter) with Laplacian Correction
The conditional probabilities for the generative naiive Bayesian classifier model where obtained from the frequencies in Table 2.1 (Bessiere et al., Bayesian programming, 2014, p.33) according to the Laplacian correction (p.27). The resulting probabilities can be found in Table 2.3 (p. 33). The WebCHURCH run computes the estimated aposterior P(Spam=true | Fortune=false, Next=true, Programming=true, Money=true, You=false) = 0.0027 which deviates from the true aposterior P(Spam=true | Fortune=false, Next=true, Programming=true, Money=true, You=false) = 0.00134393 by the |deviation| = 0.00135607. The code can be found here.