BCM-Ch03.6: Joint Distributions - The Survey Model -
BCM-Ch03.6: Joint Distributions - The Survey Model -
BCM-Ch03.6: Joint Distributions - The Survey Model -
"To make the problem concrete, suppose there are five helpers distributing a bundle of surveys to house. It is known that each bundle contained the same number of surveys, n, but the number itself is not known. The only available relevant information is that the maximum bundle is nmax = 500, and so n must be between 1 and nmax.
In this problem, it is also not known what the rate of return for the surveys is. But, it is assumed that each helper distributed to houses selected in a random enough way that it is reasonable to believe the return rates are the same. It is also assumed to be reasonable to set a uniform prior on this common rate theta ~ Beta(1,1).
Inferences can simultaneously be made about n and theta from the observed number of surveys returned for each of the helpers. Assuming the surveys themselves can be identified with their distributing helper when returned, the data will take the form of m = 5 counts, one for each helper, giving the number of returned surveys for each." (Lee & Wagenmakers, Bayesian Cognitive Modeling, 2013, p.51)
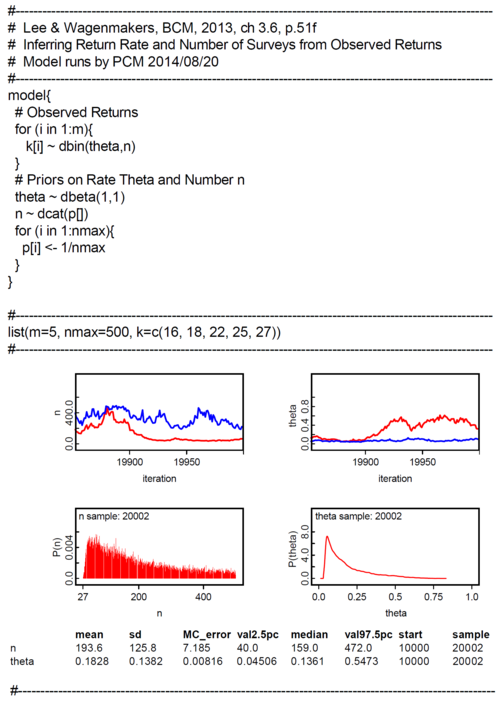
BCM-Ch03.6: OpenBUGS-Code and -Output for the 'Survey Model'
WinBUGS-Code and data are taken from Lee & Wagenmakers, 2013, p.51. We ran both in OpenBUGS. Model code and OpenBUGS output are below.
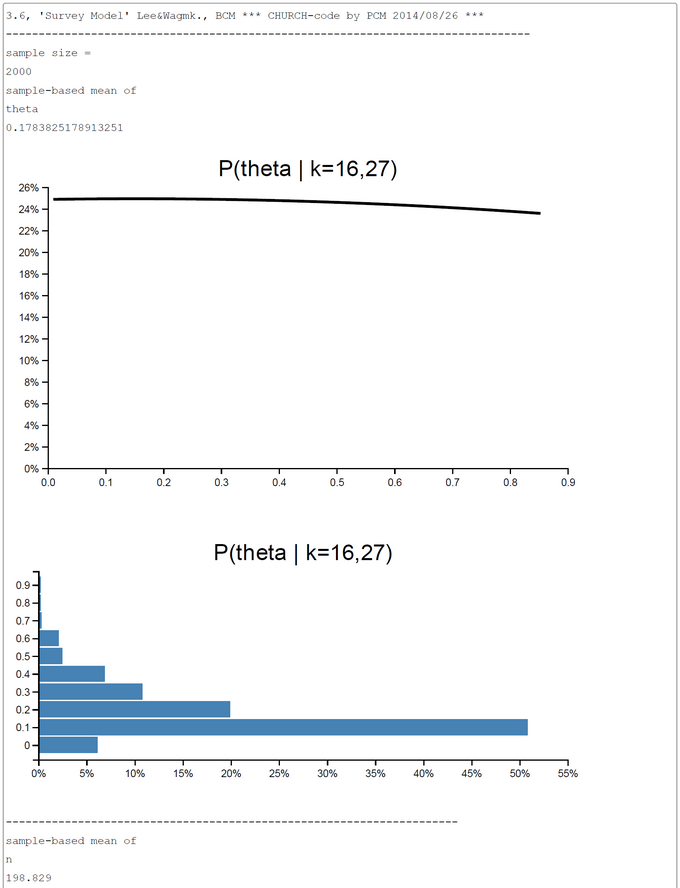
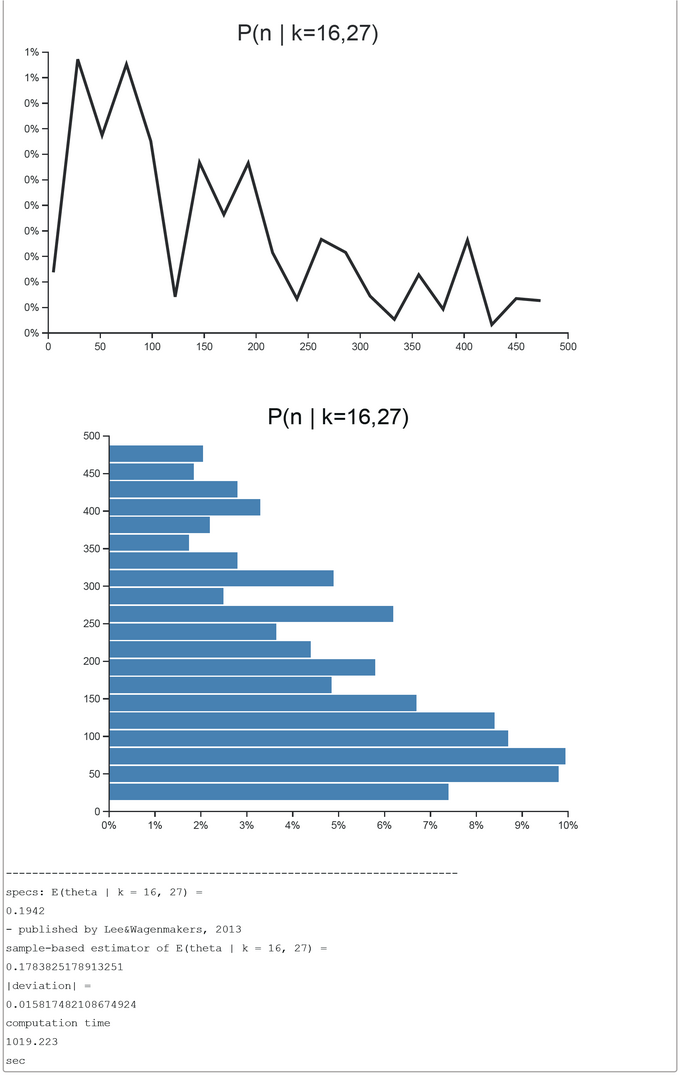
BCM-Ch03.6: Rejection-sampling-based CHURCH-Code and -output for 'Survey Model'
BUGS contains an abstract simple functional modelling language with restricted expressiveness (e.g.: an IF and recursivion is lacking). Furthermore the sampling process is rather opaque to the user. So BUGS appears to be a 'black box' to the modeler. We believe that our modeling approach with CHURCH is more transparent. Besides the random number generators, the density and the histogram plots every programming construct we used is pure functional Scheme. So it is easy to translate the CHURCH-programs to any functional programming language with similar attributes (random number generators, basic graphic routines).
Furthermore we study how far we could go when the sampling process is restricted to the easy to understand rejection sampling. Though CHURCH offers more sophisticated samplers like MCMC we prefer up to now rejection sampling. This has a clear semantics compared to GIBBS-sampling or MCMC. We believe that nearly all textbook examples could be modelled along our Poor Programmer's Probabilistic Programming Approach: Pure Functional Programs + Random Number Generators + Basic Graphic Routines + Rejection Sampling.
The WinBUGS-code from Lee & Wagenmakers is translated by us to a functional CHURCH program to clarify its semantics. The generative model is contained in the CHURCH function "take-a-sample". This code of this function should be equivalent to the model{...}-part of OpenBUGS. The number of samples taken was set to 2000 in this run. This number could in principle be increased to get a better precision of estimates. The sampling method used is the simple-to-understand 'forward sampling'. The screen-shot presented was generated by using the PlaySpace environment of WebCHURCH.
Though CHURCH claims to be a pure functional probabilistic programming language it is lacking tail-recursion optimization at the moment. Even tail-recursive calls without any actual arguments add new stack frames to the stack. The result are stack overflows which would have not happened if CHURCH would have been implemented like R6RS-compatible SCHEMEs.
This is the reason that our CHURCH-based 'Survey Model' is restricted to compute the posterior distribution of theta and n only for two helpers at the time. To avoid stack-overflow we had to modify our program. Now we avoid the tail-recursive call of 'take-a-sample' within 'take-a-sample'. Instead within 'take-a-sample' the built-in 'rejection-query' function is called. Obviously this is translated to a JavaScript-Loop. For more helpers the rejection-sampling based estimation procedure runs into an exponential runtime complexity problem.
This is the reason to abandon rejection sampling in favor of MCMC-sampling.


BCM-Ch03.6: Markov-Chain-Monte-Carlo-(MCMC)-based CHURCH-Code and -output for 'Survey Model'
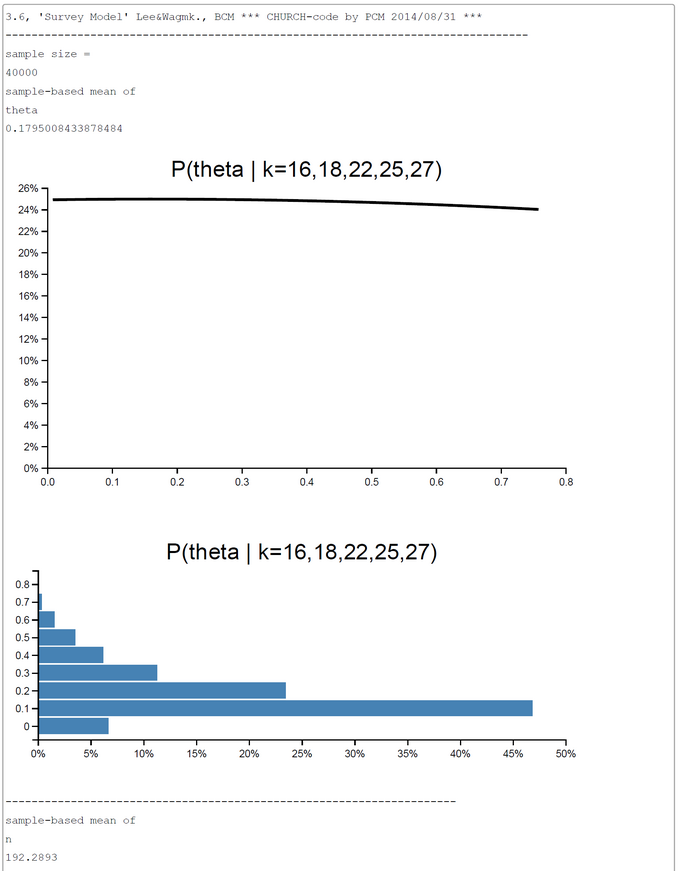
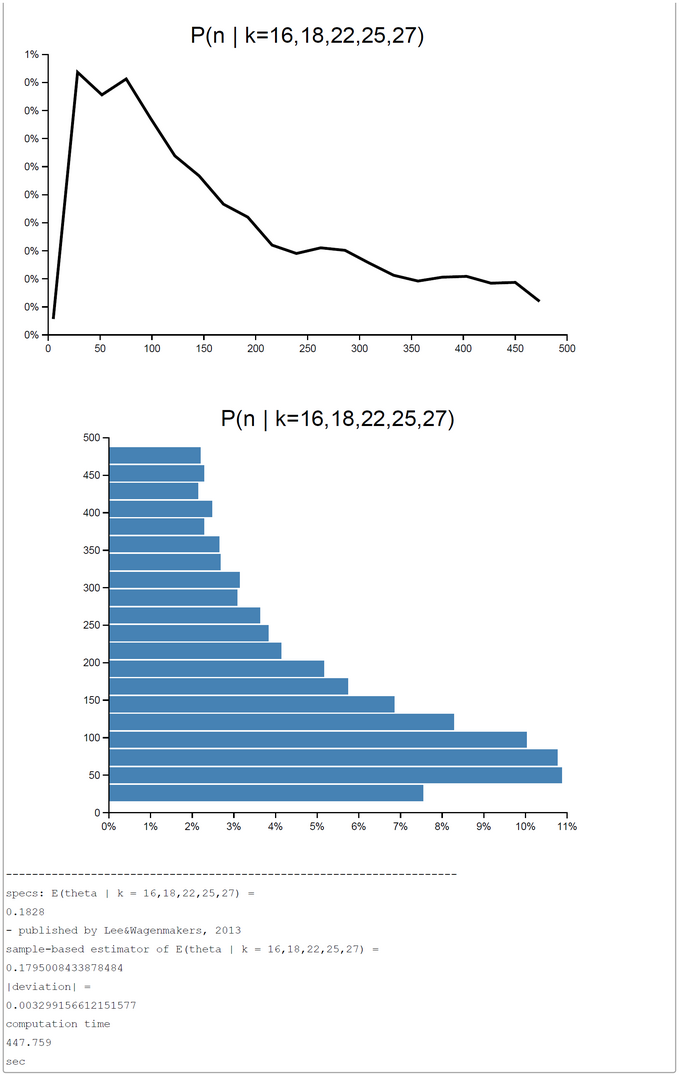
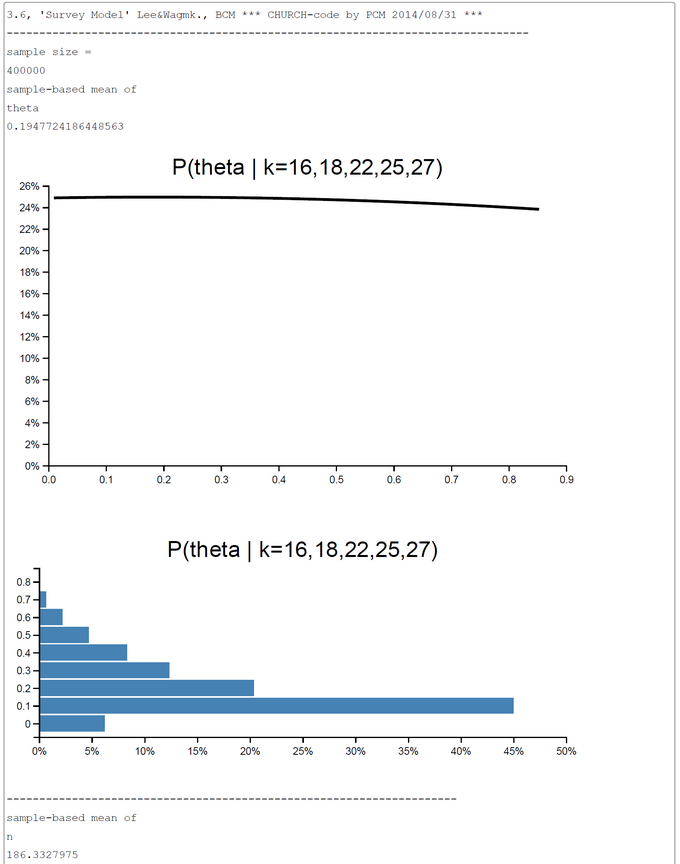
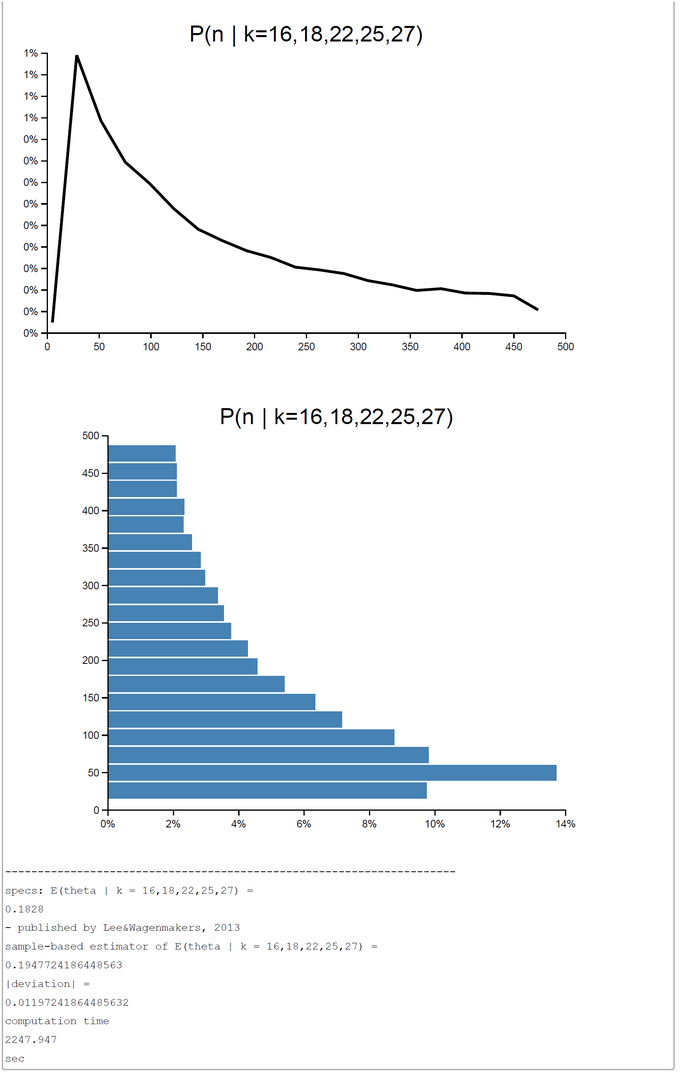
For the MCMC-sampling process the code has to be changed slightly. The code is selfexplanatory. We show two runs; the first with 40.000 samples (447.759 sec), and the second with 400.000 samples (approx. 38 min computation time). The both runs show a close agreement with the OpenBUGS results. In the first run the |deviation| = |theta-Openbugs - theta-WebCHURCH| = 0.00329, and in the second run the |deviation| = 0.01197. From this result we would clearly prefer the results of the first runs, whereas the second rund with 400.000 samples generates are more smoothly posterior distribution for the n's.